
紙媒体から文字入力する際などに便利なOCR機能ですが、今回業務中にデータファイルを誤って消去してしまい、元ファイルが無く幸い印刷した紙だけが残ってある状態。一から入力も面倒だったので、Adobe Acrobat DC OCR機能を使って復元作業を行いました。
基本的には文字の認識の精度も高く、ほぼほぼ正確に認識して復元することができましたので今回はAdobe AcrobatのOCRの使い方とレビューをご紹介します。
OCRで読み取りしたいファイルをAdobe Acrobatで開く。
まずはOCRで読み取りたいファイルをAdobe Acrobatで開きます。
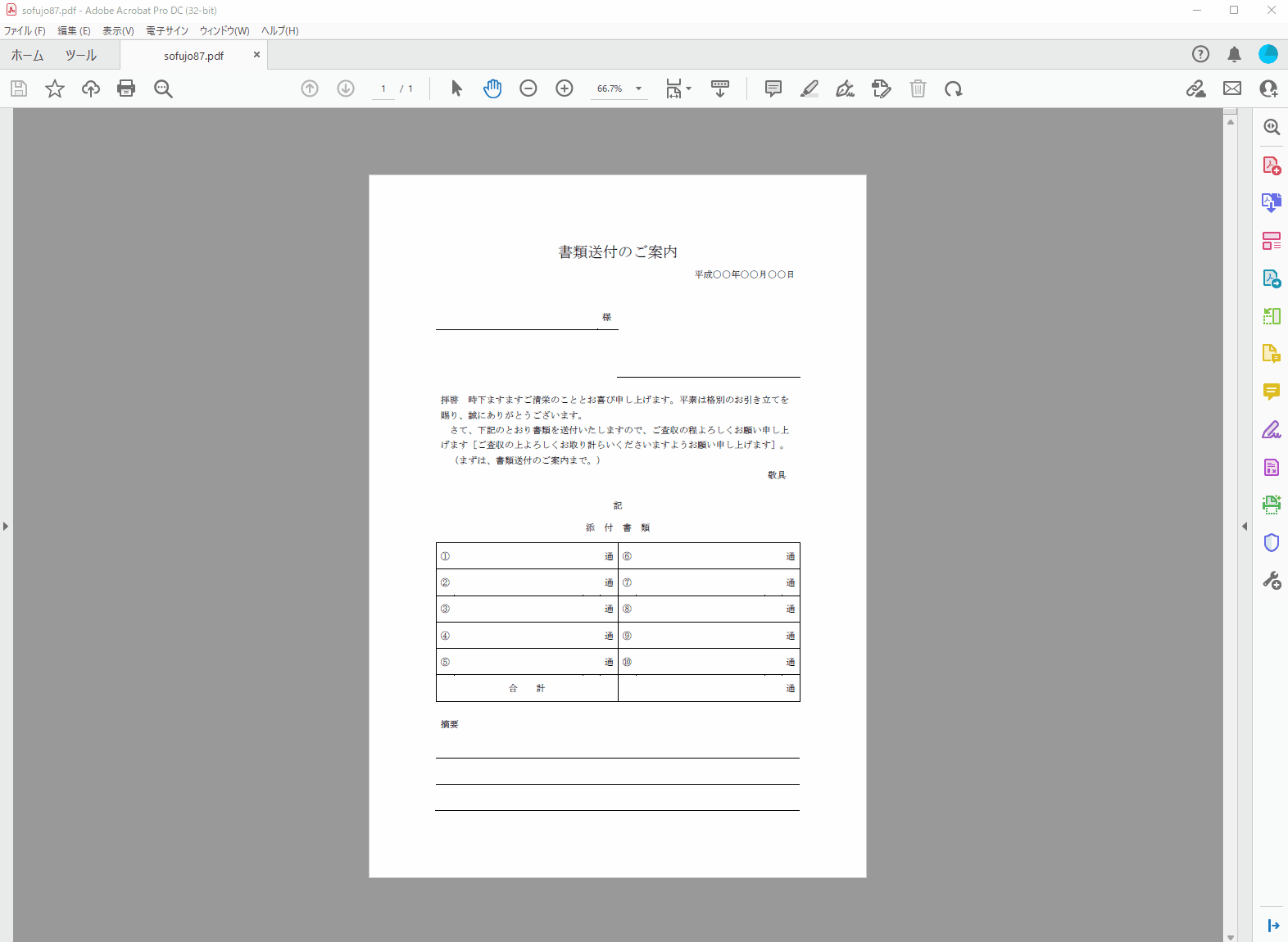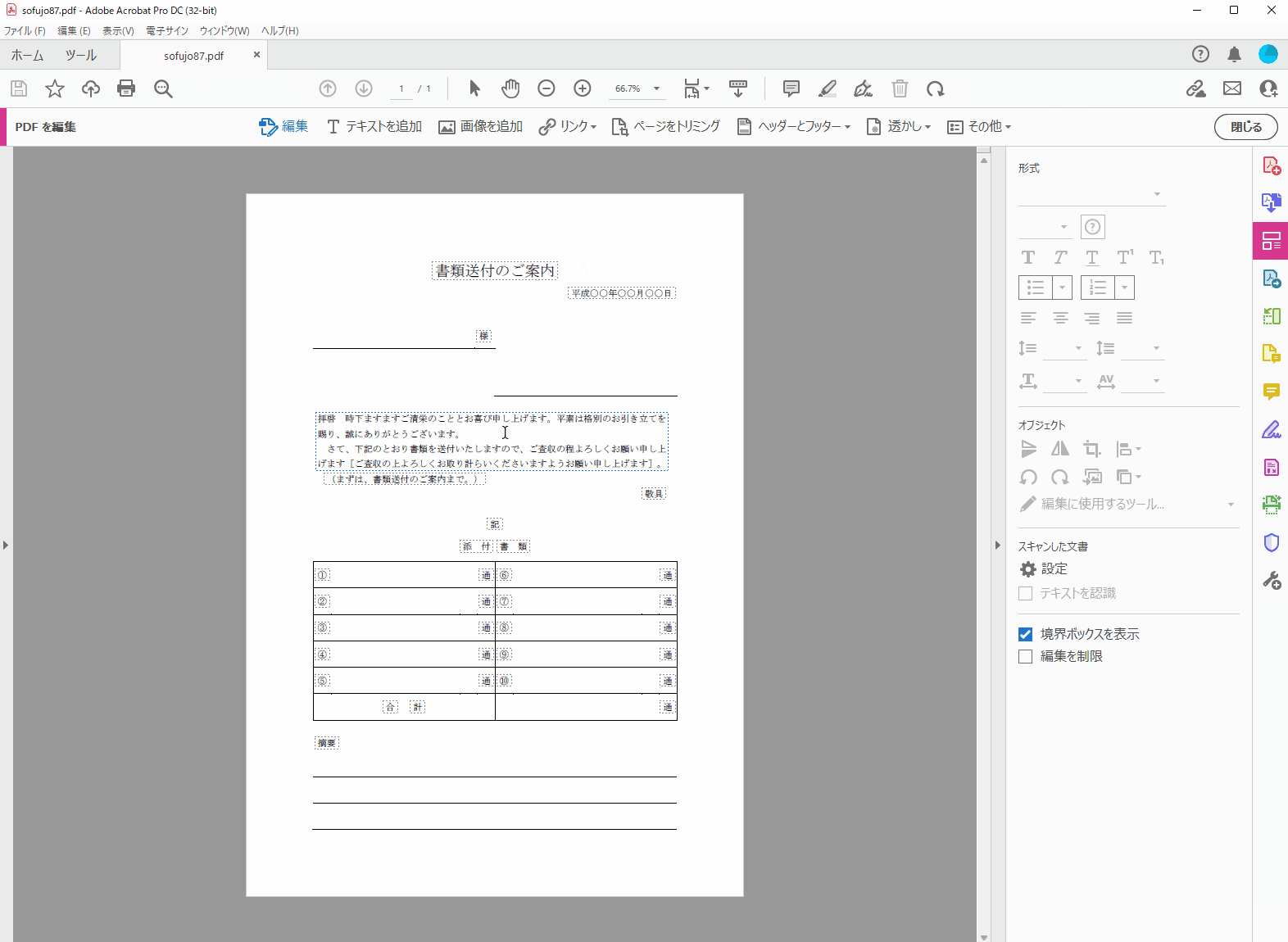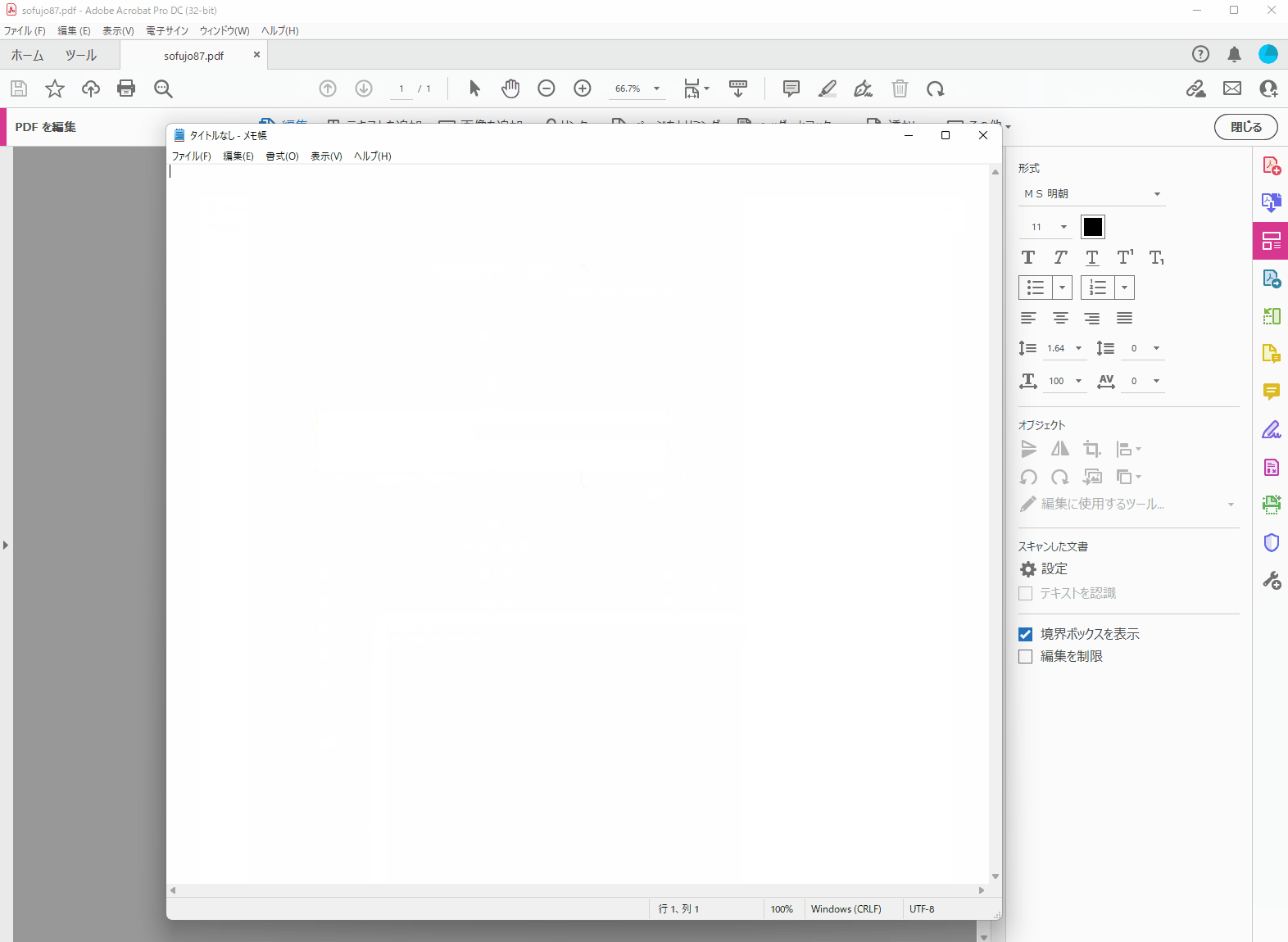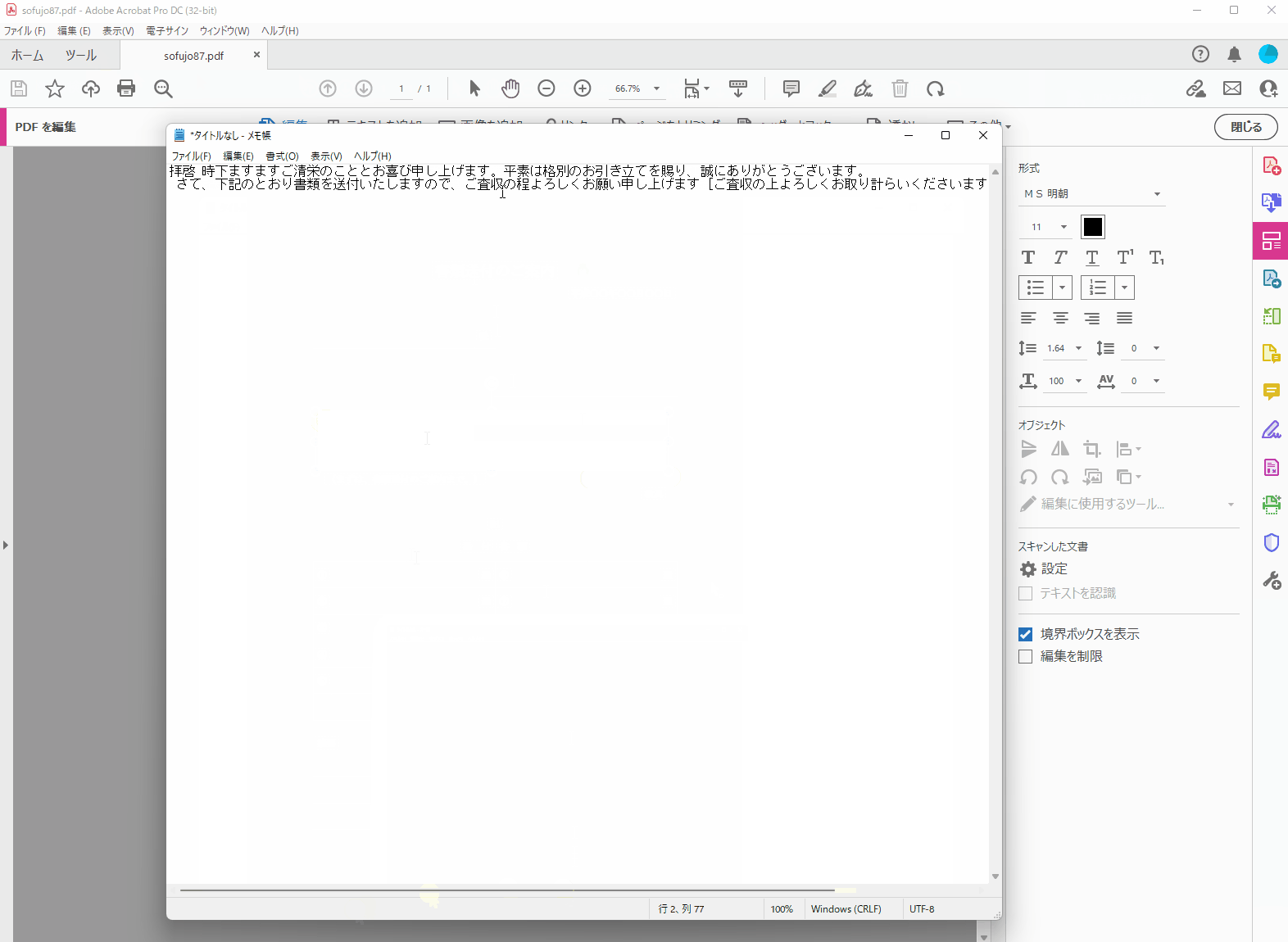
ファイルを開いたらツールタブをクリックしてPDFを編集をクリックします。読み込みが完了すると上記画像のようにファイル内に破線の囲い枠が表示されますので、囲い枠内の文章を選択して、メモ帳やwordなどにコピペしてやります。
注意点
- Adobe Acrobatは当然ですが、PDFでしか認識ができませんので、スキャナで読み取る際にはPDFファイルで生成などの設定が必要です。jpegなどの場合はpdfに変換するなどの手間が発生します。
- 今回の記事には業務書類でスキャンしたものは掲載できていませんが、スキャナで読み取った時に、文字のかすれなどがあると正確な変換ができない事があります。また手書き等も試したのですが、手書きの場合も誤変換が多発しました。
過去にスキャナ等で添付のソフトを使用した事があったのですが、誤変換が多く使い物になりませんでしたが、今回検証したAdobe Acrobatは精度も高く、紙媒体からのファイル復元が容易にできました。
文字のかすれ・手書きなどはまだまだ認識が難しいですが、文字起こしや紙媒体からのデータ入力には便利なツールです。
リンク